|
I am a PhD student in the UC Berkeley EECS department advised by Prof. Ion Stoica. My research interests are in Artificial Intelligence and Systems. I am associated with SkyLab and Berkeley Artificial Intelligence Research (BAIR). Before that, I earned my M.S. in EECS under Ion Stoica and Ken Goldberg from AUTOLab during 2021. I also earned a B.S. from UC Berkeley with a double major in EECS and Business Administration in 2020. Email / CV / Google Scholar / LinkedIn / Github |

|
|
Currently, my research involves building scalable systems for ML pracitioners that will fulfill the Sky Computing vision. We are open source. This research involves virtualizing GPUs to scale DL training to trillions of parameters and designing learnable scheduling policies for migrating jobs across different and regions clouds (incl. on-premise). Previously,my masters's and undergraduate research primarily focused on practical problems and applications for reinforcement learning (RL), including NLP, query optimization for databases, and video streaming. |
|
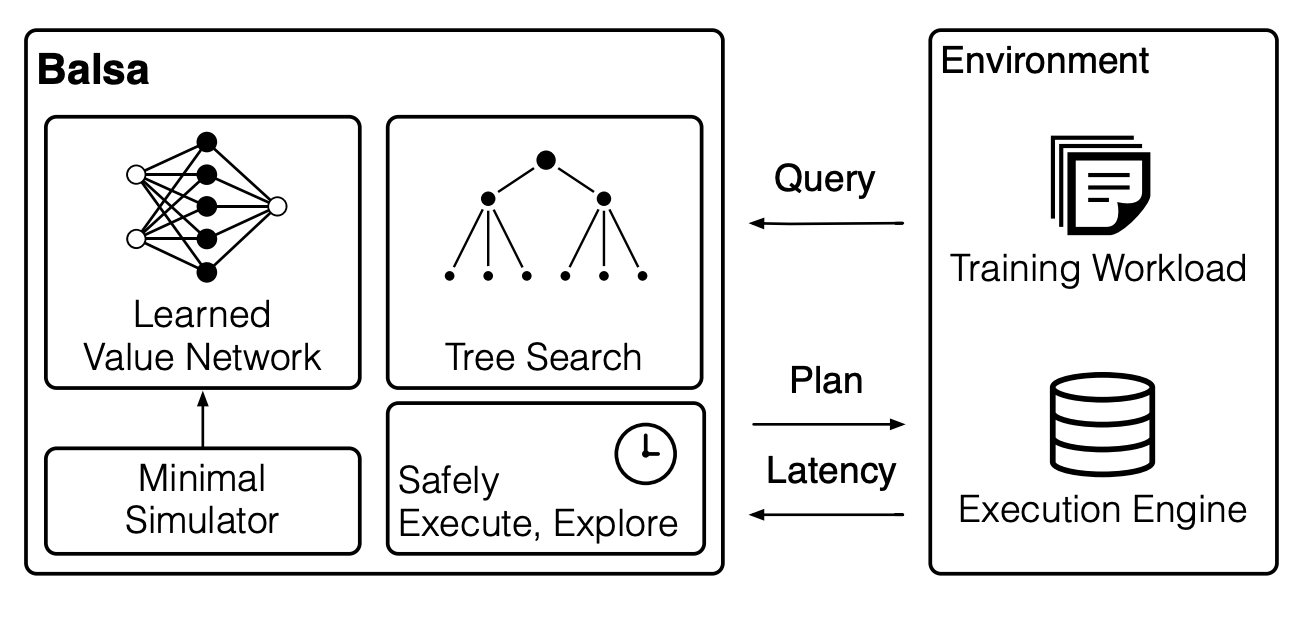
Zongheng Yang, Wei-lin Chiang, Frank Luan, Gautam Mittal, Michael Luo, Ion Stoica Special Interest Group on Management of Data (SIGMOD), 2022 Arxiv | Video | Code An end2end query optimizer trained via deep RL that exceeds the query-performance of expert solvers by up to 2.8x. |
|
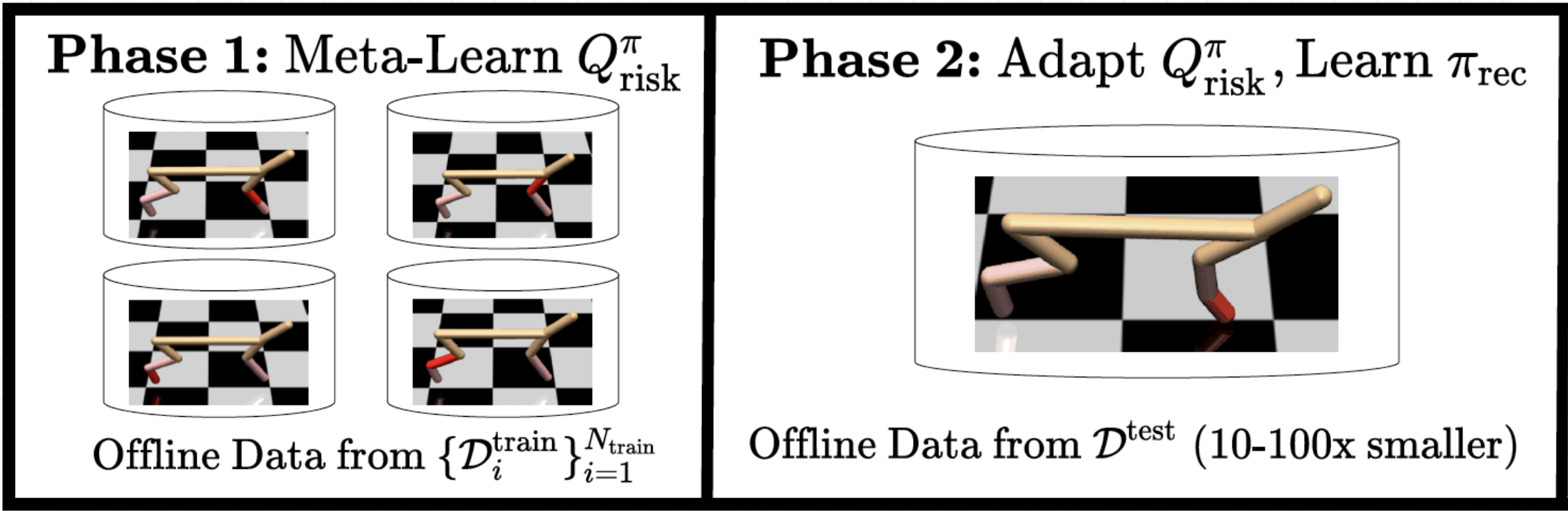
Michael Luo, Ashwin Balakrishna, Brijen Thananjeyan, Suraj Nair, Julian Ibarz, Jie Tan, Chelsea Finn, Ion Stoica, Ken Goldberg Neural Information Processing Systems (NeurIPS) Safe Control Workshop, 2021 Website | Arxiv | Video | Code Safe RL algorithm that meta-learns from offline datasets to safely adapt to unseen environments. |
|
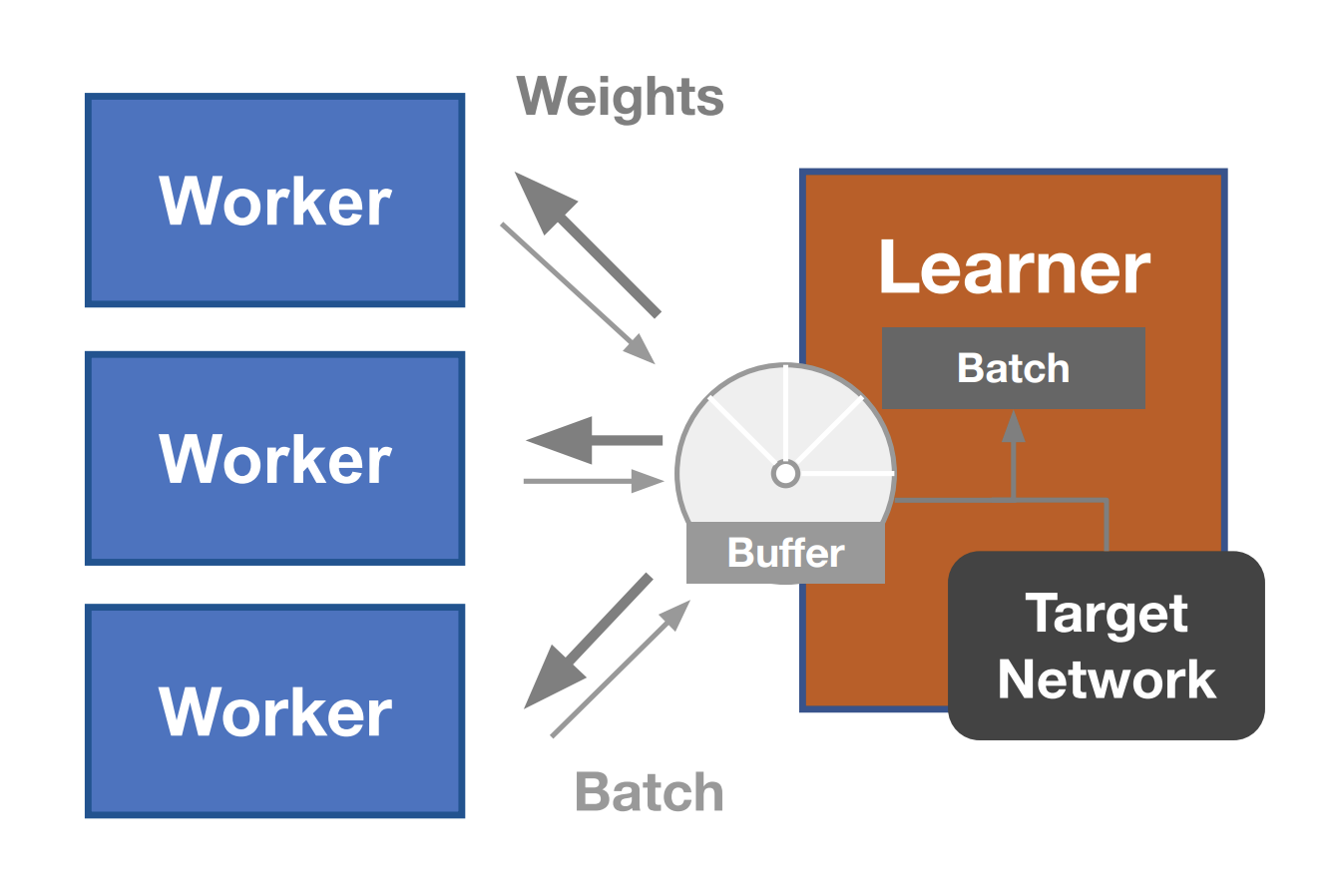
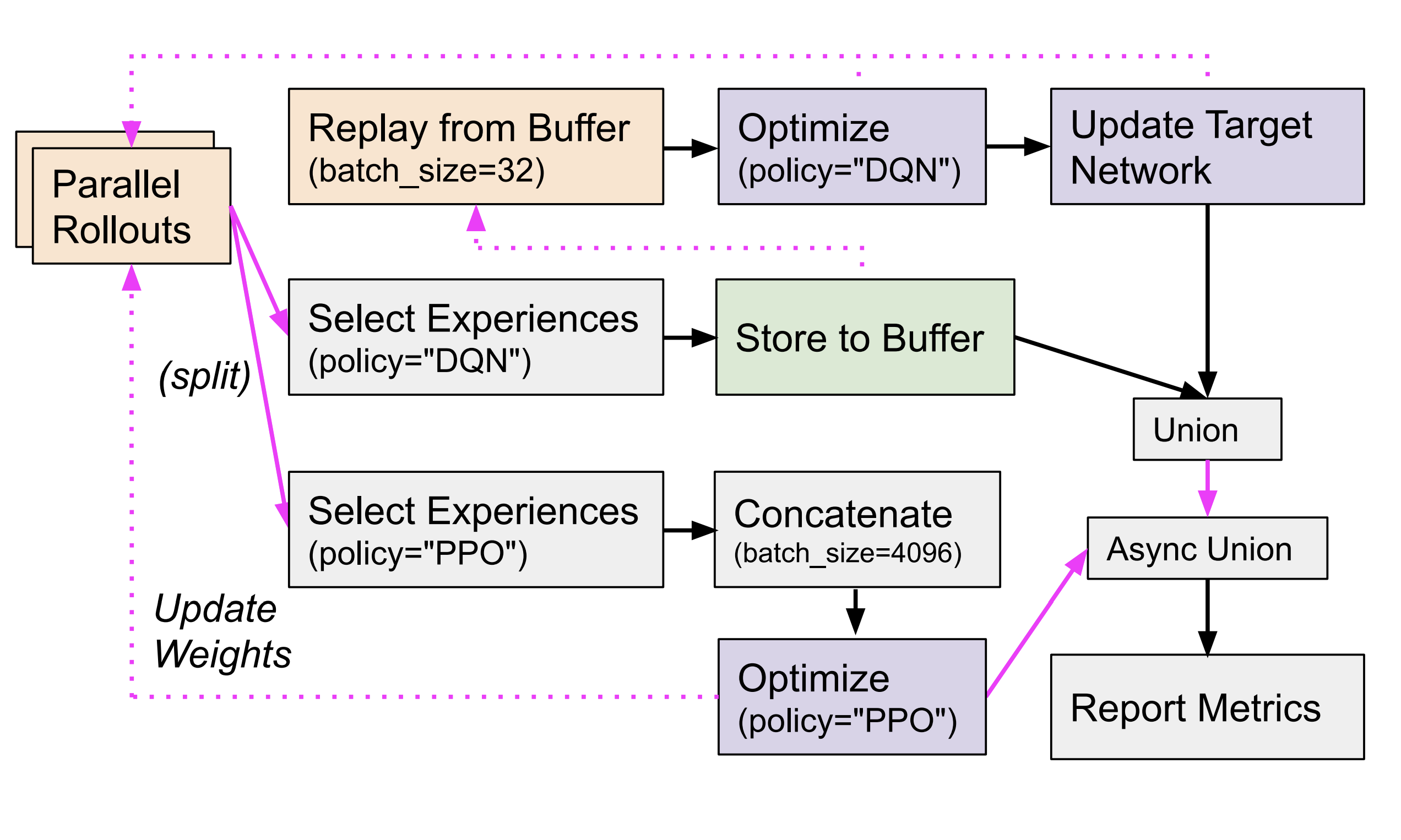
Michael Luo, Jiahao Yao, Richard Liaw, Eric Liang, Ion Stoica International Conference on Learning Representations (ICLR), 2020 Website | Arxiv | Video | Code An algorithm for distributed reinforcement learning that tunes the tradeoff between distributed data collection and learning sample efficiency to optimize for training speed by combining the sample efficiency of PPO and the data throughput from IMPALA. |
|
Rachit Dubey*, Erin Grant*, Michael Luo*, Karthik Narasimhan, Thomas L. Griffiths Preprint. Arxiv | Code We introduce a framework for using contextual information about a task to guide the initialization of task-specific models before adaptation to online feedback, which leads to faster adaptation to online feedback than that of zero-shot multitask approaches. |
|
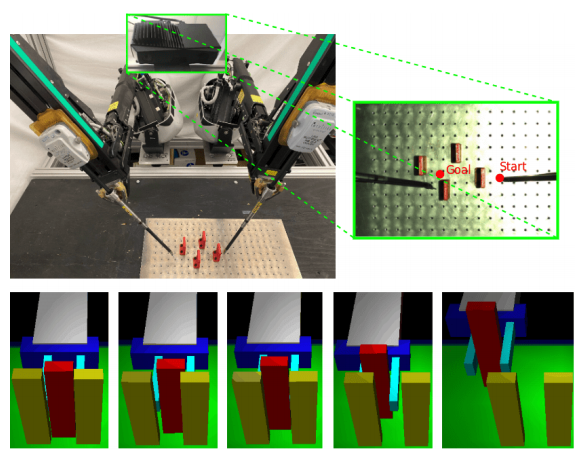
Brijen Thananjeyan*, Ashwin Balakrishna*, Suraj Nair, Michael Luo, Krishnan Srinivasan, Minho Hwang, Joseph E. Gonzalez, Julian Ibarz, Chelsea Finn, Ken Goldberg International Conference on Robotics and Automation (ICRA), 2021 Website | Arxiv | Video | Code An algorithm for safe reinforcement learning which utilizes a set of offline data to learn about constraints before policy learning and a pair of policies which separate the often conflicting objectives of task directed exploration and constraint satisfaction to learn contact rich and visuomotor control tasks. |
|
Eric Liang*, Zhanghao Wu*, Michael Luo, Sven Mika, Ion Stoica Neural Information Processing Systems (NeurIPS), 2021. Arxiv | Video | Code We propose RLFlow, a hybrid actor-dataflow programming model for distributed RL, that leads to highly composable and performant implementations of RL algorithms, which results to faster training and significant code reductions. |
|
|
Jeffrey Ichnowski, Paras Jain, Bartolomeo Stellato, Goran Banjac, Michael Luo, Francesco Borrelli, Joseph E. Gonzalez, Ion Stoica, Ken Goldberg Neural Information Processing Systems (NeurIPS), 2021. Website | Arxiv | Video | Code An intelligent application of RL that tunes the parameters of existing Quadratic Program (QP) solvers and improving solving times by up to 3x. |

|
Xuanlin Li*, Brandon Trabucco*, Dong Huk Park, Yang Gao, Michael Luo, Sheng Shen, Trevor Darrell International Conference on Learning Representations (ICLR), 2021. Website | Arxiv | Video | Code We propose the first domain-independent unsupervised / self-supervised learner that discovers high-quality autoregressive orders through fully-parallelizable end-to-end training without domain-specific tuning. |
|
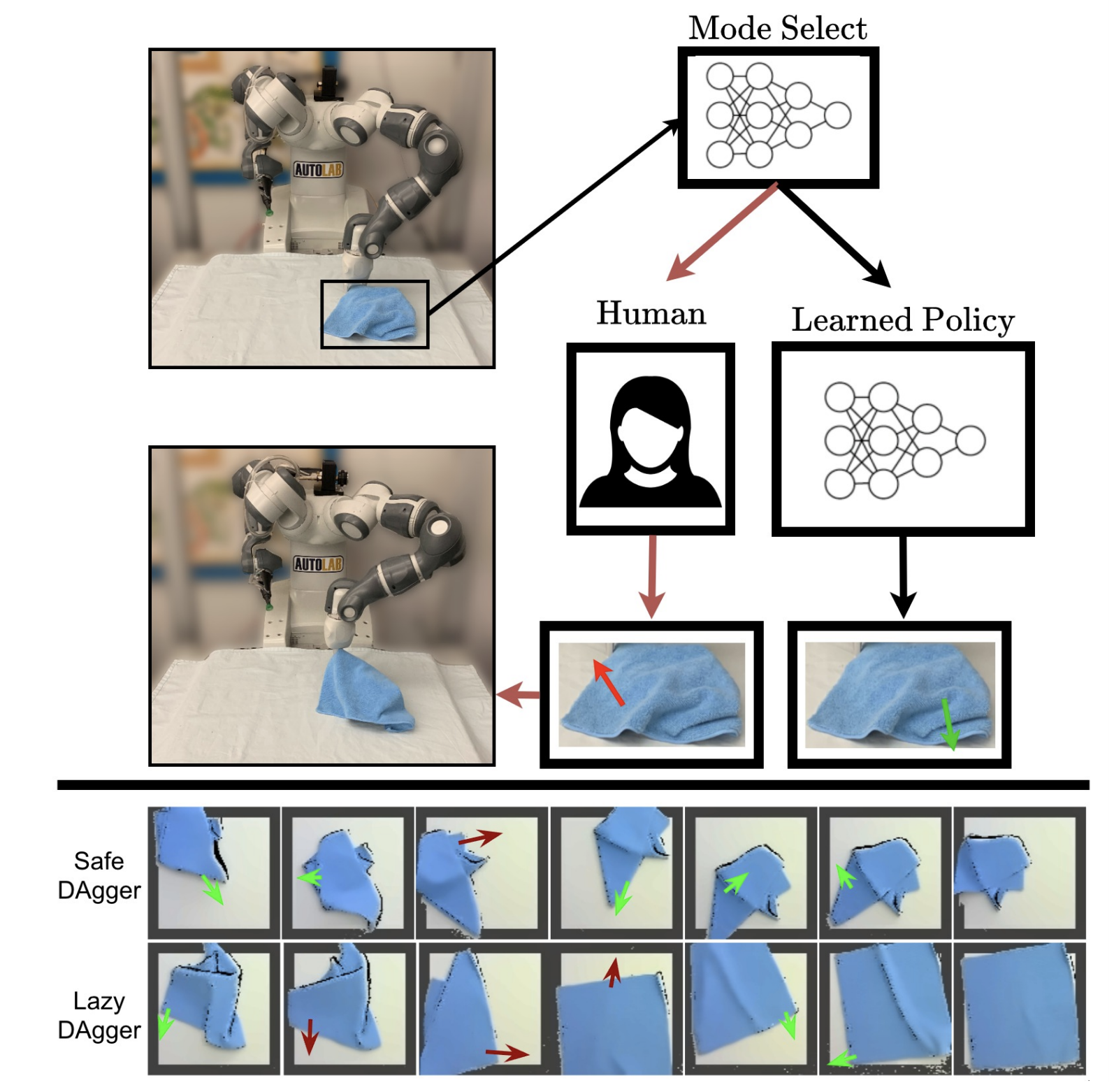
Ryan Hoque, Ashwin Balakrishna, Brijen Thanajeyan, Carl Putterman, Michael Luo, Daniel Seita, Daniel S. Brown, Ken Goldberg Conference on Automation Science and Engineering (CASE), 2021. Website | Arxiv | Video An algorithm for interactive imitation learning that learns to minimize human context switching through sustained interventions and maintains the same supervisor burden for prior algorithms. |

|
Yahav Avigal, Anna Deza, William Wong, Sebastian Oehme, Mark Presten, Mark Theis, Jackson Chui, Paul Shao, Huang Huang, Atsunobu Kotani, Satvik Sharma, Michael Luo, Stefano Carpin, Joshua Viers, Stavros Vougioukas, Ken Goldberg International Conference on Robotics and Automation (ICRA), 2021 Website | Paper | Code We investigate different seed placement and pruning algoritms in a polyculture garden simulator to jointly maximize diveristy and coverage of various plants types. |
|
|
 |
Core contributor; Developed Sky Storage, Sky On-premise, and multi-node core features. |
 |
Core contributor; Created distributed model-free, model-based, and meta-learning RL algorithms on RLlib, including APPO/IMPACT, MAML, MBMPO, and Google Dreamer. |
|
|

|
CS 189: Introduction to Machine Learning
CS 162: Operating Systems and System Programming |
|
|
 |
Anyscale
Software Development Intern |
 |
Amazon
Software Development Intern |
 |
Cisco Meraki
Computer Vision Intern |
|
|