|
I am currently building a stealth startup. My interests lie broadly in building next generation AI systems and models (e.g. efficient serving and post-training). Previously, I was at Google DeepMind, where I worked on efficient agentic systems for serving and post-training. I created the Agentica Project, an open-source initiative for post-training language agents via RL, producing models like DeepScaleR, DeepCoder, and DeepSWE with over 2M+ downloads. Our training recipes are published on the rLLM framework. I received my PhD in EECS from UC Berkeley, where I was advised by Ion Stoica and was part of SkyLab and BAIR. I also hold an M.S. and B.S. (CS & Business) from UC Berkeley. |

|
|
For a full list, see my publications page or Google Scholar. |
|
|
An open-source initiative for post-training language agents via reinforcement learning. Agentica models have achieved over 2M+ downloads on HuggingFace. We've optimized RL systems and published training recipes on the rLLM project, now maintained by academia, with over 5K+ stars.
|
|
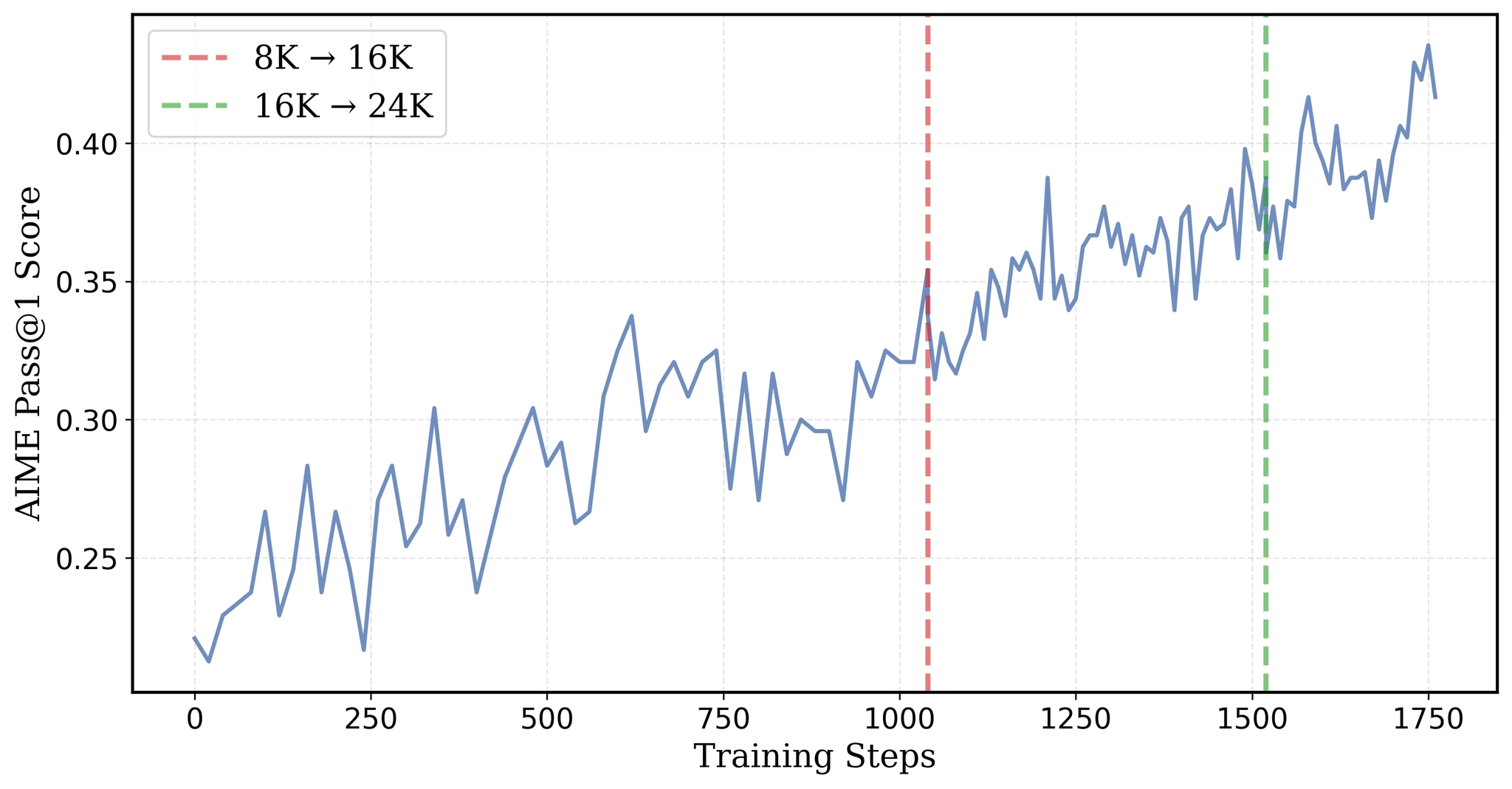
Michael Luo, Sijun Tan, Justin Wong, Xiaoxiang Shi, William Y. Tang, Manan Roongta, Colin Cai, Jeffrey Luo, Li Erran Li, Raluca Ada Popa, Ion Stoica Notion Blog, Feb. 2025 Blog |
|
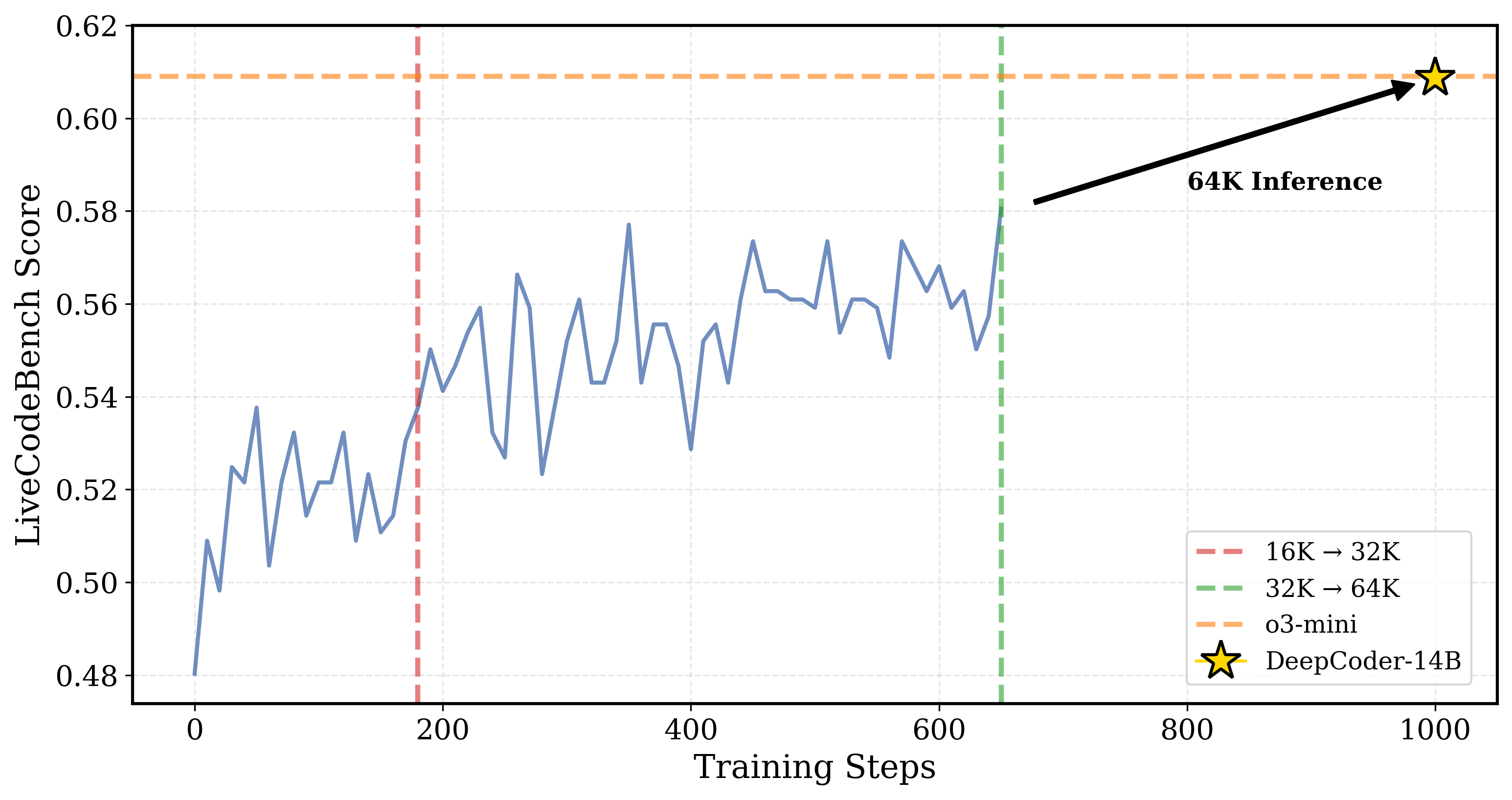
Michael Luo, Sijun Tan, Roy Huang, Ameen Patel, Alpay Ariyak, Qingyang Wu, Xiaoxiang Shi, Rachel Xin, Colin Cai, et al. Notion Blog, Apr. 2025 Blog |
|
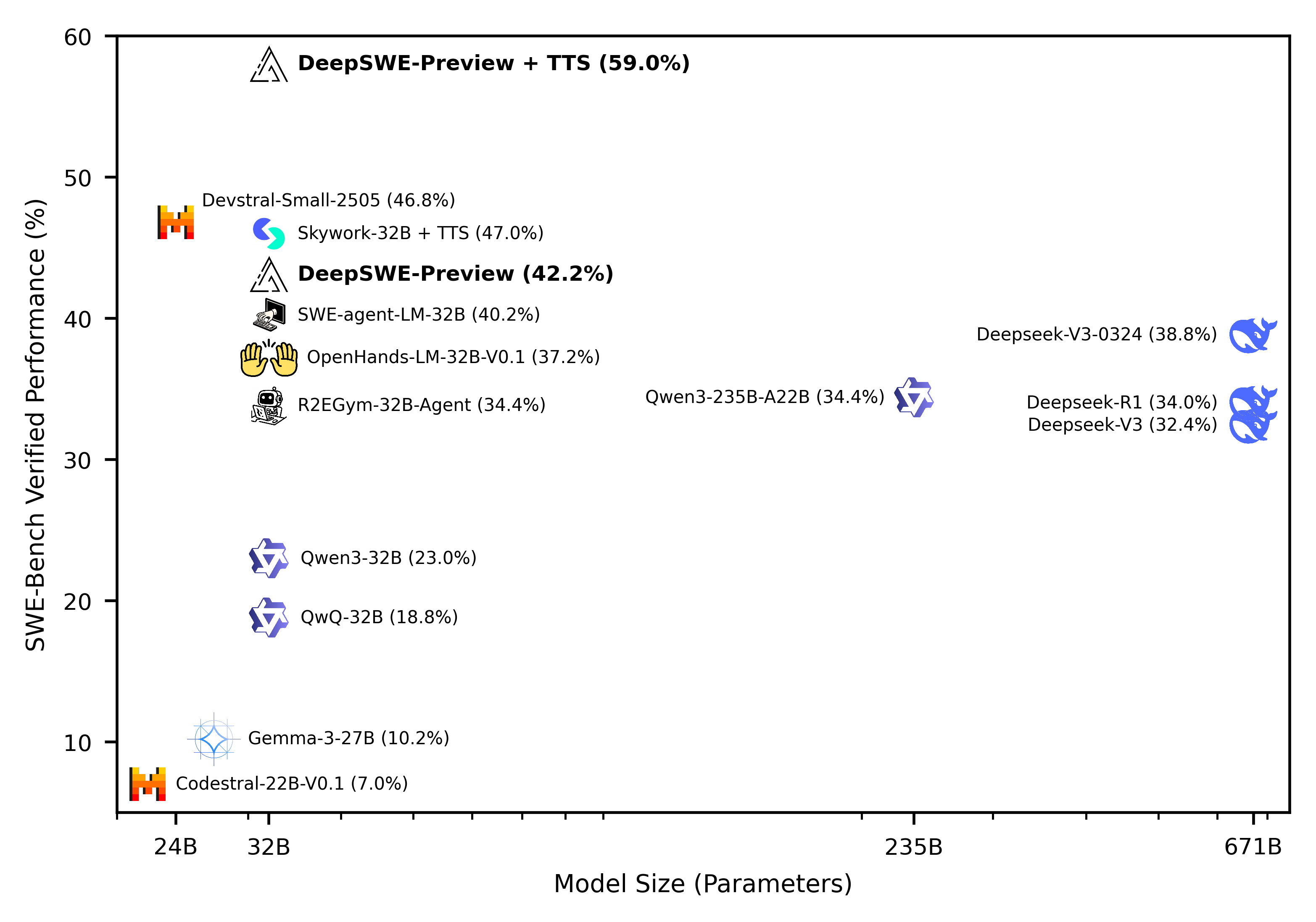
Michael Luo, Naman Jain, Jaskirat Singh, Sijun Tan, Ameen Patel, Qingyang Wu, Alpay Ariyak, Colin Cai, Tarun Venkat, et al. Notion Blog, Jun. 2025 Blog |

|
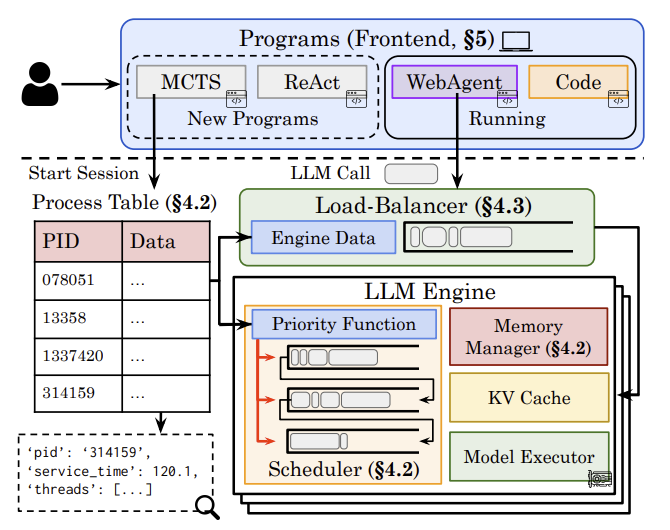
Sijun Tan*, Michael Luo*, Colin Cai*, Tarun Venkat, Kyle Montgomery, Aaron Hao, Tianhao Wu, Arnav Balyan, Manan Roongta, Chenguang Wang, Li Erran Li, Raluca Ada Popa, Ion Stoica Notion Blog, Jun. 2025 Blog | Code |
|
Michael Luo, Xiaoxiang Shi, Colin Cai, Tianjun Zhang, Justin Wong, Yichuan Wang, Chi Wang, Yanping Huang, Zhifeng Chen, Joseph E. Gonzalez, Ion Stoica USENIX Symposium on Networked Systems Design and Implementation (NSDI), 2026 Arxiv | Paper |

|
Michael Luo, Justin Wong, Brandon Trabucco, Yanping Huang, Joseph E. Gonzalez, Zhifeng Chen, Ruslan Salakhutdinov, Ion Stoica Neural Information Processing Systems (NeurIPS), 2024 Oral Arxiv | Talk |
|
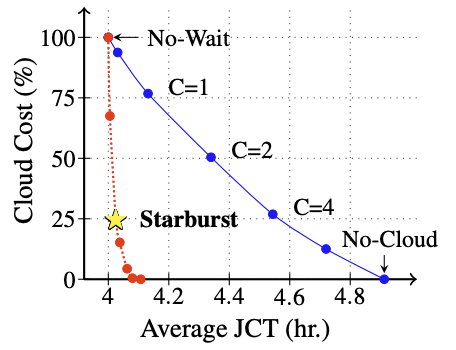
Michael Luo, Siyuan Zhuang, Suryaprakash Vengadesan, Romil Bhardwaj, Justin Chang, Eric J. Friedman, Scott Shenker, Ion Stoica USENIX Annual Technical Conference (USENIX ATC), 2024 Best Paper Award Paper |

|
Zongheng Yang, Zhanghao Wu, Michael Luo, Wei-Lin Chiang, Romil Bhardwaj, Woosuk Kwon, Siyuan Zhuang, Frank Sifei Luan, Gautam Mittal, Scott Shenker, Ion Stoica USENIX Symposium on Networked Systems Design and Implementation (NSDI), 2023 Paper | Code |
|
|

|
University of California, Berkeley
University of California, Berkeley
University of California, Berkeley |
|
|
 |
Google DeepMind
Research Scientist, Sept 2023 - March 2025 SaxML Team; Developed and researched efficient agentic systems for serving and post-training. |
 |
Anyscale, Ray Core Team
Software Development Engineer Intern, June 2020 - Jan 2021 Scaled distributed RL training and developed asynchronous RL algorithms with Ray/RLlib. |
 |
Amazon AI
Machine Learning Engineer Intern, June 2019 - Aug 2019 Created the first embedding/RAG based recommendation system for Amazon Ads. |
 |
Cisco Meraki, Smart Camera Team
Computer Vision Engineer Intern, June 2018 - Aug 2018 Developed model-based object detection to track individuals across Meraki cameras. |